在完成了贪吃蛇游戏的基本功能后,我们将尝试实现一个能自主学习玩贪吃蛇的AI智能体。本节我们通过实现前文 提到的Q-learning算法,进一步直接体会强化学习的实现与训练过程。
log 😄 😅 = 💧 \log_{😄}😅=💧
log 😄 😅 = 💧
在Q-learning算法中,核心是维护一个用于表示动作价值的Q-table。在贪吃蛇游戏中,我们可以直观的将状态简化为以下特征。
食物相对于蛇头所处的方位:(上/中/下,左/中/右)。上/中/下与左/中/右分别使用0/1/2表示,共3 × 3 = 9 3 \times 3 = 9 3 × 3 = 9
蛇头的上/下/左/右是否存在边界或身体:(是/否,是/否,是/否,是/否)。是/否分别使用1/0表示,共2 4 = 16 2^4 = 16 2 4 = 1 6 9 × 16 = 144 9 \times 16 = 144 9 × 1 6 = 1 4 4 ( s , a ) (s,a) ( s , a ) 144 × 4 = 576 144 \times 4 = 576 1 4 4 × 4 = 5 7 6 ( 144 , 4 ) (144,4) ( 1 4 4 , 4 )
我们创建一个agents.py用于存储智能体相关代码。在本节中,我们创建QLearning类完成智能体的训练与交互。Q Q Q
1 2 3 4 5 6 7 8 class QLearning :def __init__ (self ):self .q_table = np.zeros((144 , 4 )) self .learning_rate = 0.1 self .gamma = 0.9 self .epsilon = 0.1 self .epsilon_decay = 0.999 self .time_step = 0
其中,Q Q Q
当我们获得了蛇头和食物的位置之后,我们需要按设计的状态规则对游戏信息进行抽象化。为了使代码更加模块化,我们在QLearning类中加入一个get_state方法以获取状态。get_state方法首先需要通过坐标相减的方式获取食物相对蛇头的位置。
1 2 3 4 5 6 7 def get_state (self, snake, food, done=False ):''' 获取状态,共(3 ** 2) * (2 ** 4) = 144,即食物相对蛇头的位置是否处于(上/中/下,左/中/右),蛇头(上,下,左,右)是否存在边界或身体。 ''' 0 ].top) + 1 0 ].left) + 1
在判断食物的相对方位后,对蛇头四周是否存在边界和身体进行判断。
1 2 3 4 5 6 7 8 9 10 11 12 13 0 ] * 4 for i, direction in enumerate (DIRECTIONS):0 ].topleft + np.array(DIRECTIONS[direction]) * UNITif left < 0 or left > SCREEN_X or top < 0 or top > SCREEN_Y:True elif (left, top) in [body.topleft for body in snake.body[1 :]]:True else :False
最后,我们调用numpy库中的ravel_multi_index方法,将这几维信息按形状映射到一维索引上,从而对应到Q-table中。
1 2 3 3 , 3 , 2 , 2 , 2 , 2 ))return state_index
通过get_state方法,我们将具体的游戏信息映射到了对应的状态索引上,从而可以在Q-table中查询此状态下对应的所有动作价值。
在动作选择过程中,我们采用ϵ \epsilon ϵ Q Q Q
1 2 3 4 5 6 7 8 9 def choose_action (self, state ):if np.random.uniform() < self .epsilon:4 )else :self .q_table[state])return action
Q Q Q
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s,a) \leftarrow Q(s,a) + \alpha \left[ r + \gamma \max_{a^\prime} Q(s^\prime, a^\prime) - Q(s,a) \right]
Q ( s , a ) ← Q ( s , a ) + α [ r + γ a ′ max Q ( s ′ , a ′ ) − Q ( s , a ) ]
注意到当一局游戏进行到最后一步,即蛇死亡的最后一步时,“下一状态” 并不存在。故最后一步的更新公式直接根据即时奖励进行更新:
Q ( s , a ) ← Q ( s , a ) + α [ r − Q ( s , a ) ] Q(s,a) \leftarrow Q(s,a) + \alpha \left[ r - Q(s,a) \right]
Q ( s , a ) ← Q ( s , a ) + α [ r − Q ( s , a ) ]
1 2 3 4 5 6 7 8 9 10 11 def learn (self, s, a, r, s_, done ):self .q_table[s, a] if done:else :self .gamma * np.max (self .q_table[s_]) self .q_table[s, a] += self .learning_rate * (q_target - q_predict) self .epsilon = max (self .epsilon * self .epsilon_decay, 0.01 ) self .time_step += 1
至此,我们完成了对QLearning类的定义,从而使其具备基本的参数迭代能力。然而,我们仍需对主程序进行修改,以使Q-learning算法的训练和推理完全嵌入到贪吃蛇游戏中。
在完成了Q-learning算法的实现和智能体的定义后,我们需要将Q-learning的训练和推理能力完整地嵌入到贪吃蛇游戏中,实现一个基于强化学习的自动玩贪吃蛇的智能体。本节将详细讲解如何设计游戏主程序,使Q-learning算法能够训练智能体并通过训练结果进行推理。
1 2 3 4 5 MODEL = 'QLearning' False 0
在游戏的每一帧中,智能体需要实时获取当前的游戏状态,并根据状态选择动作。通过调用get_state方法,智能体将游戏环境(如蛇头位置、食物位置、障碍物位置等)编码为一个唯一的状态表示。随后,利用ϵ \epsilon ϵ choose_action方法决定下一步的动作。在这一阶段,智能体会在探索和利用之间进行权衡:在训练初期,智能体倾向于探索更多的随机动作以获取环境信息;而在训练后期,随着探索率逐渐衰减,智能体会更多地依赖Q-table中存储的策略,选择当前最优动作。
1 2 3 4 5 s = agent.model.get_state(snake, food)if not KEYBOARD_CONTROL:
根据Q-learning算法的设计,智能体执行动作后,游戏环境会发生变化。蛇将根据选择的方向移动,同时更新其状态(如位置和长度)。在这个过程中,我们需要根据游戏规则设计合适的即使奖励机制。在本例中,当蛇吃到食物时,给予+10的即时奖励;当蛇撞到墙壁或自身时,给予惩罚性的-10的即时奖励。在许多问题中,往往一开始智能体很难通过随机的策略获得成功的奖励,这时我们可以设计过程中的奖励或惩罚来引导其成功。在本例中,我们根据蛇头与食物之间的曼哈顿距离给予适度的负奖励,以激励蛇向食物靠近的行为,从而加速训练过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 r = 0 if snake.body[0 ].colliderect(food.rect): 1 ].copy()) 1 10 elif snake.is_dead():10 True print (f"Episode {episode+1 } , Score: {score} " )else :0 ].left, snake.body[0 ].top0.1 * (abs (head_left - food_left) + abs (head_top - food_top)) / 22
在完成动作执行和奖励计算后,智能体需要通过learn方法更新Q-table的值。Q-learning的核心在于使用当前状态、动作、奖励以及下一状态,对 Q-table 中对应的状态动作对进行更新。通过这一过程,智能体能够逐渐学习到哪些动作在特定状态下是最优选择,从而优化游戏表现。
1 2 3 4 5 6 if done:break
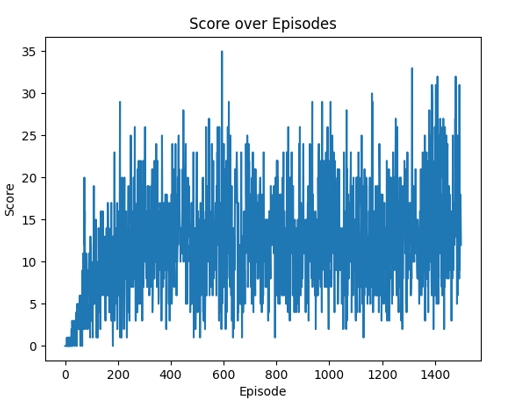
当游戏结束时(如蛇撞到墙壁或自身),智能体会输出当前回合的得分,并将游戏环境重置,开始下一轮训练。通过不断循环这一过程,智能体能够在多次训练中逐步提高表现。最终,智能体可以在没有人工干预的情况下高效地玩贪吃蛇游戏。
图1 Q-learning算法得分随轮次变化折线图