在上一篇文章中,我们使用DQN算法实现了一个基于深度神经网络的强化学习智能体。虽然通过神经网络的函数近似突破了Q-learning算法的局限性,但当前的实现仍然存在一些改进空间。本文将从状态建模和网络结构两个角度对智能体进行优化,以进一步提升智能体的学习效果。
log 😄 😅 = 💧 \log_{😄}😅=💧
log 😄 😅 = 💧
在之前的实现中,我们仅采用了一个3 × 12 × 12 3 \times 12 \times 12 3 × 1 2 × 1 2
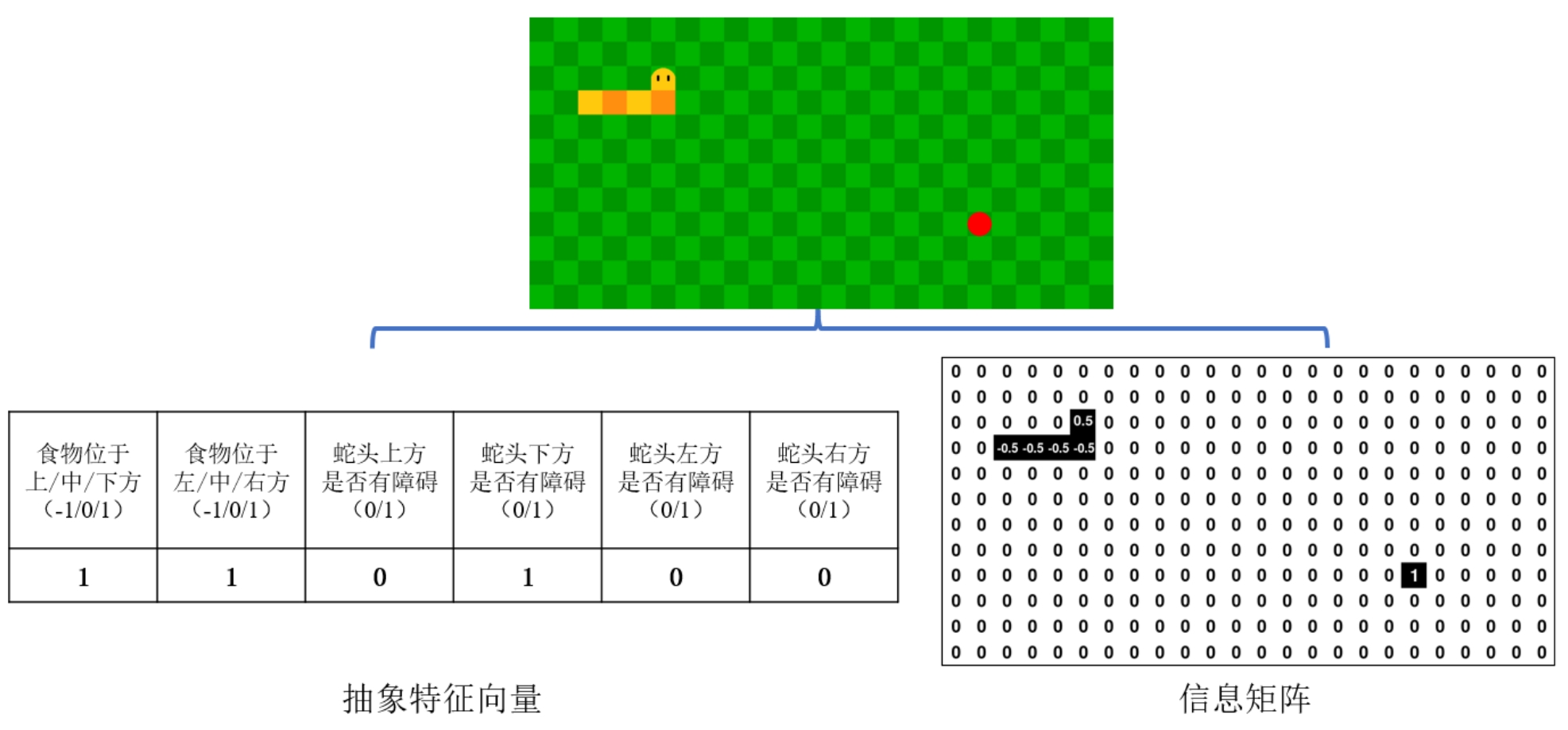
在本次优化中,我们将游戏状态建模为特征矩阵和人工特征的混合表示。(地图大小更改为12 × 24 12 \times 24 1 2 × 2 4
特征矩阵表示:使用一个12 × 24 12 \times 24 1 2 × 2 4
食物位置对应的元素设为1
蛇头位置对应的元素设为0.5
蛇身位置对应的元素设为-0.5
其他位置元素设为0
人工特征表示:总结游戏的关键信息为抽象特征向量
食物相对于蛇头的方位特征:使用(-1,0,1)表示(上/中/下,左/中/右)
蛇头四个方向的障碍物特征:使用(0/1)表示(无/有)障碍物
图1 优化后的状态表示
这种混合状态表示的优势在于:
特征矩阵保留了完整的游戏空间信息
人工特征提供了更直接的决策依据
不同形式的特征互为补充,提供了更丰富的状态表达
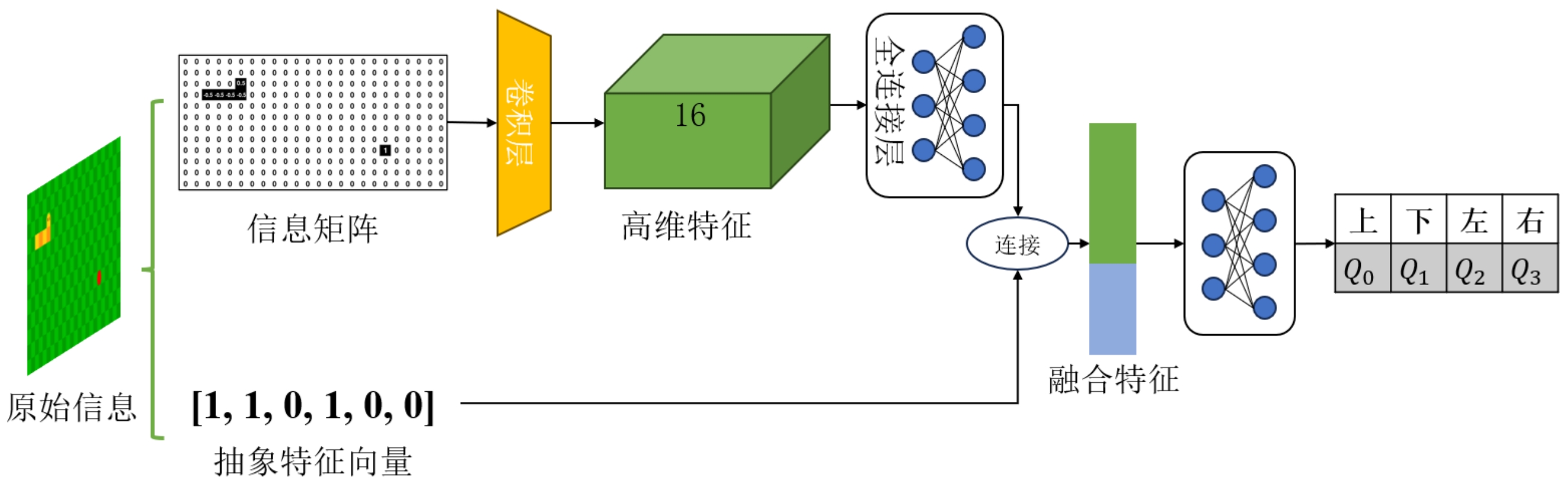
为了更好地处理混合状态输入,我们设计了一个双输入的神经网络结构,如图1所示:
图2 优化后的网络结构
特征矩阵处理分支:
输入层:1 × 12 × 24 1 \times 12 \times 24 1 × 1 2 × 2 4
卷积层:使用16个3 × 3 3 \times 3 3 × 3
全连接层:将卷积特征压缩至10维向量
人工特征处理分支:
输入层:6维的人工特征向量
全连接层:直接与卷积特征分支的输出拼接
合并层:
将两个分支的特征向量拼接为16维向量
通过全连接层映射到4维输出,对应四个动作的Q值
网络结构的具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Net (nn.Module):def __init__ (self ):super (Net, self ).__init__()self .conv = nn.Sequential(1 , -1 ),1 , 16 , kernel_size=3 ), self .conv_fc = nn.Sequential(16 *12 *24 , 10 ),self .fc = nn.Sequential(16 , 4 ),def forward (self, x ):self .conv(feature_matrix)self .conv_fc(feat)1 )return self .fc(x)
对应新的状态表示方式,我们需要修改状态获取函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 def get_state (self, snake, food, done=False ):if done:1 , 1 , 12 , 24 ), dtype=np.float32)1 , 6 ), dtype=np.float32)return input_tensor, feature_matrix0 ]1 :]12 , 24 ), dtype=np.float32)1 0.5 for body in snake_body:0.5 1 , 1 , 12 , 24 )0 ].top) + 1 0 ].left) + 1 0 ] * 4 for i, direction in enumerate (DIRECTIONS):0 ].topleft + np.array(DIRECTIONS[direction]) * UNITif left < 0 or left > SCREEN_X or top < 0 or top > SCREEN_Y:True elif (left, top) in [body.topleft for body in snake.body[1 :]]:True else :False 1 , 6 )return input_tensor, feature_matrix
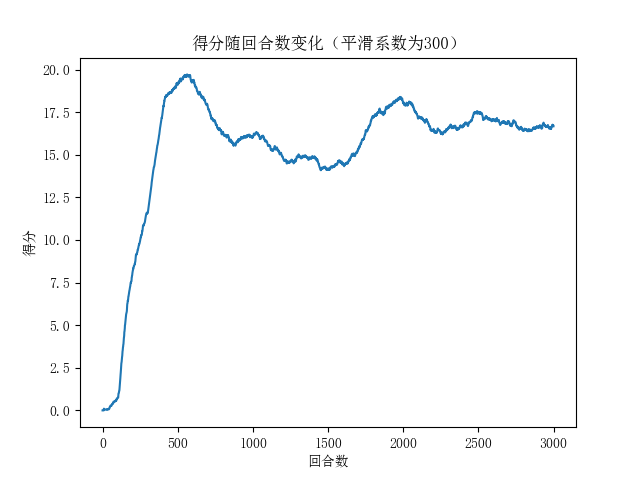
优化后的模型训练效果如图2所示:
图3 优化后的训练曲线
从训练曲线可以看出:
学习速度显著提升:在前500回合内模型就表现出明显的学习效果
最终性能提高:平均得分从原来的2-8分提升到15-17分左右
这种性能的提升主要得益于:
混合状态表示提供了更丰富的环境信息
双输入网络结构能更好地处理不同形式的特征
人工特征为智能体提供了更直接的决策依据
本文通过优化状态表示和网络结构,显著提升了DQN智能体在贪吃蛇游戏中的表现。混合状态建模和双输入网络的设计思路也为类似的强化学习任务提供了有益的参考。这些优化不仅提高了智能体的学习效率和最终性能,也增强了模型的稳定性,展现了深度强化学习在复杂环境中的应用潜力。